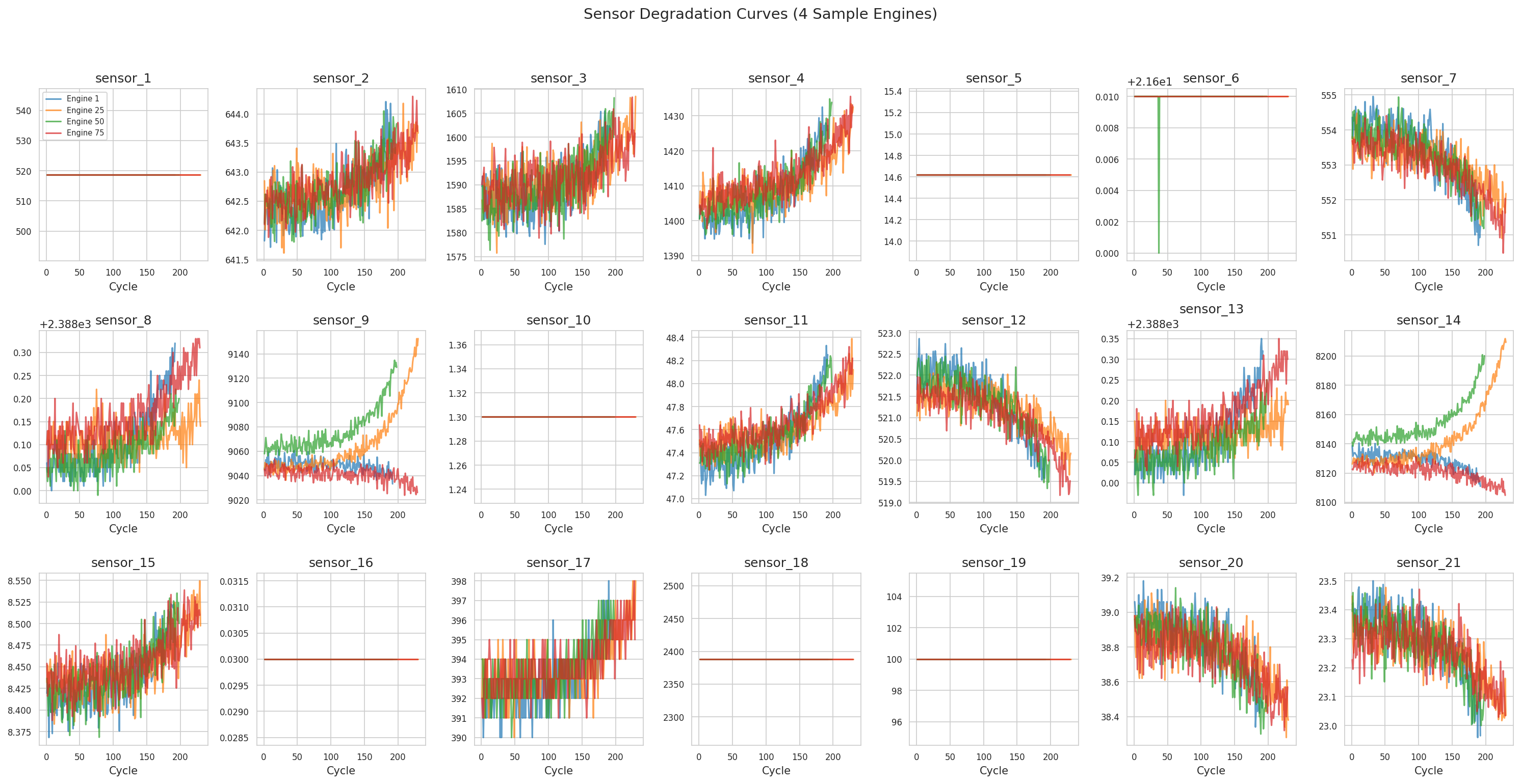
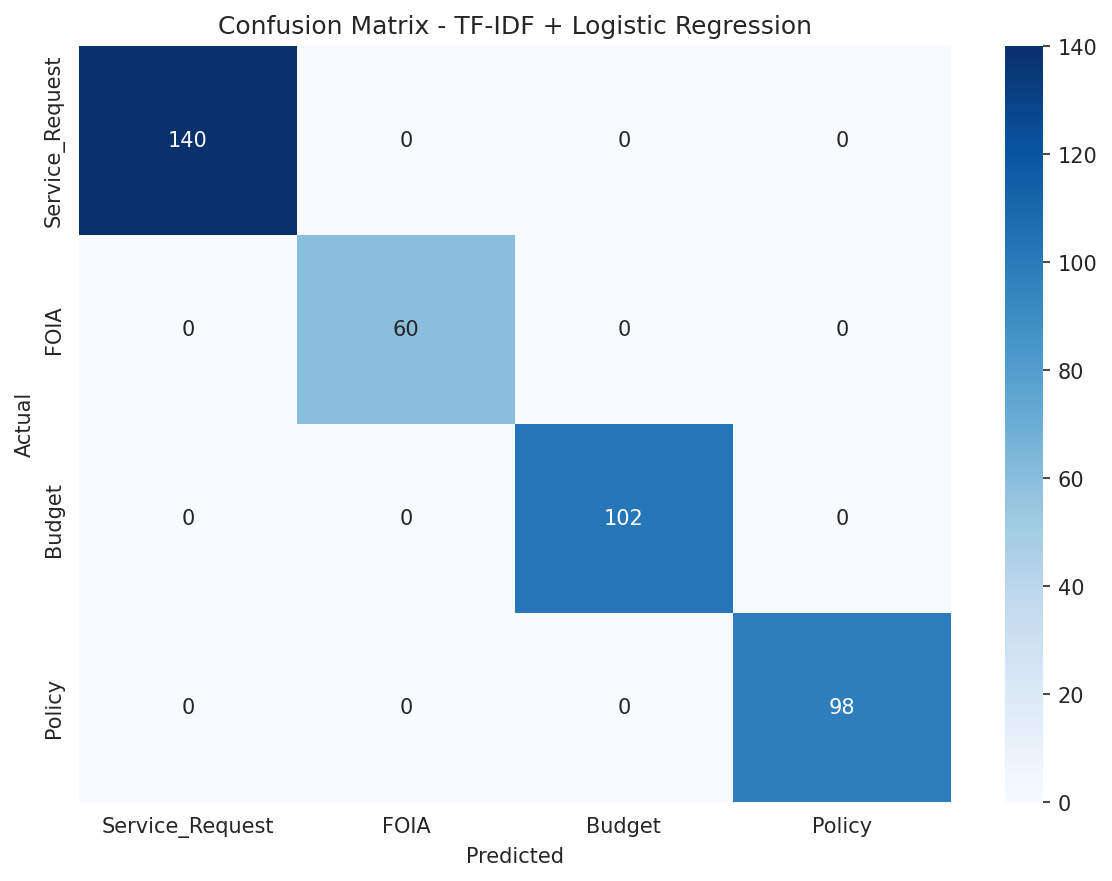
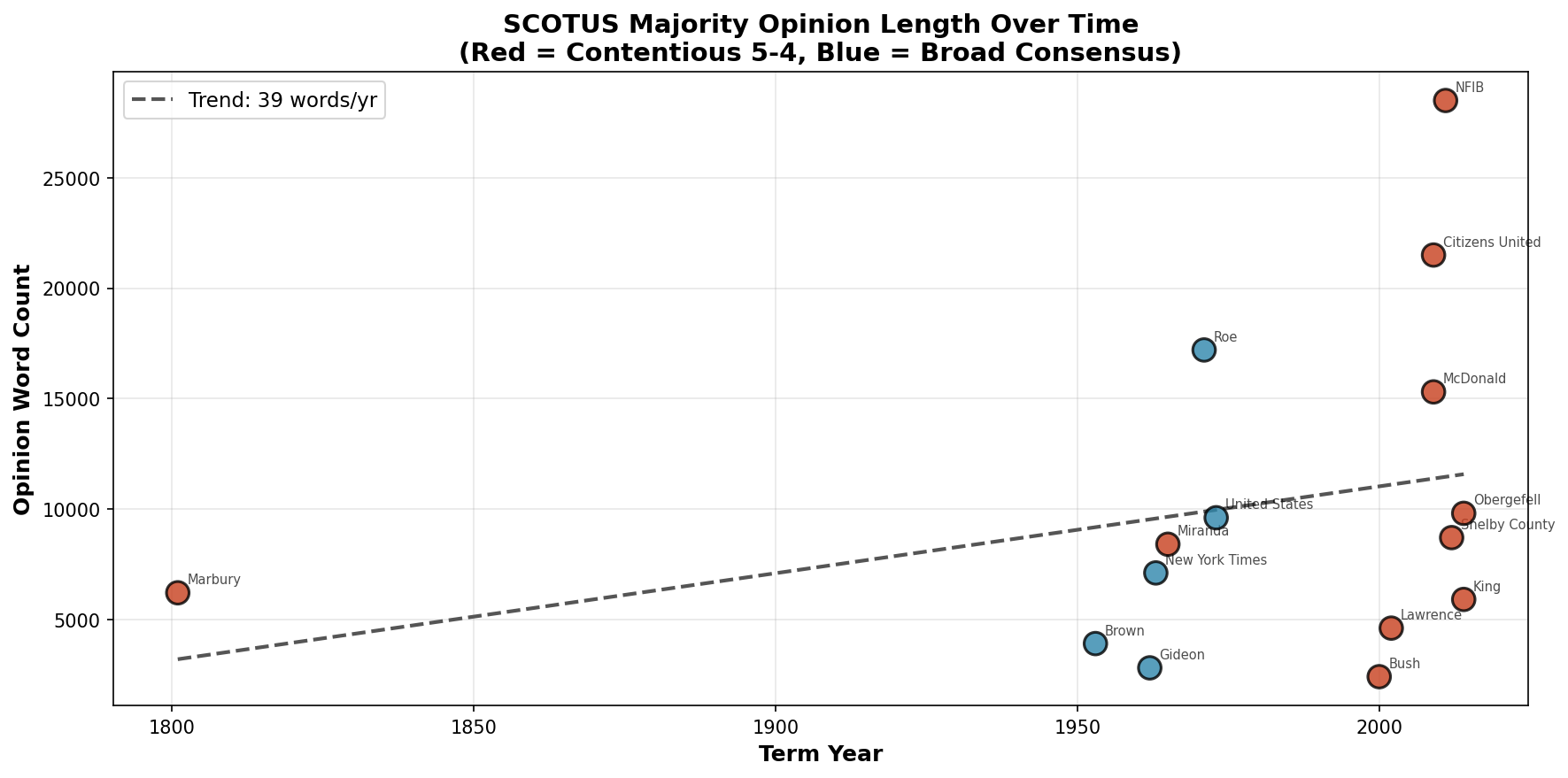
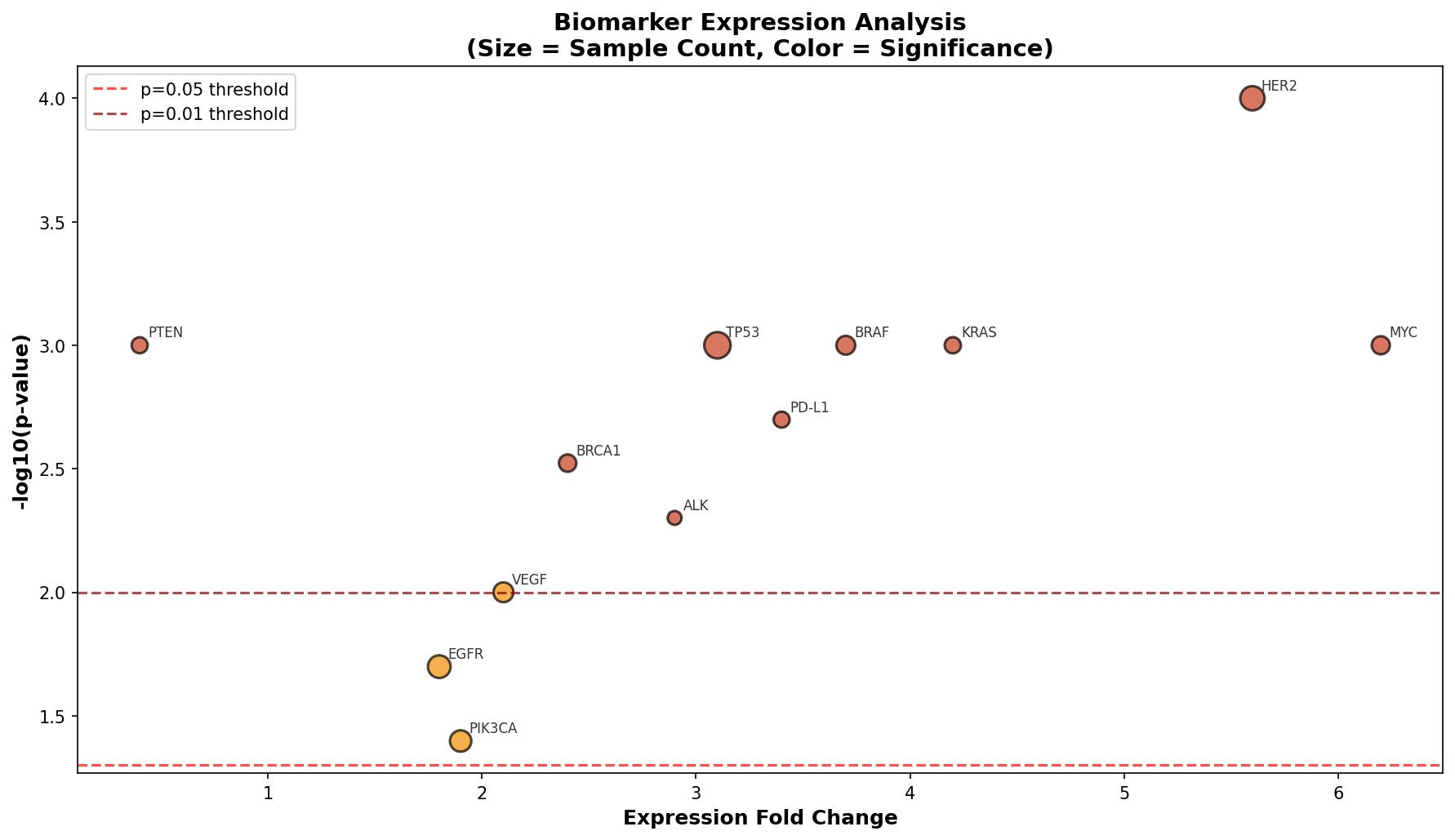
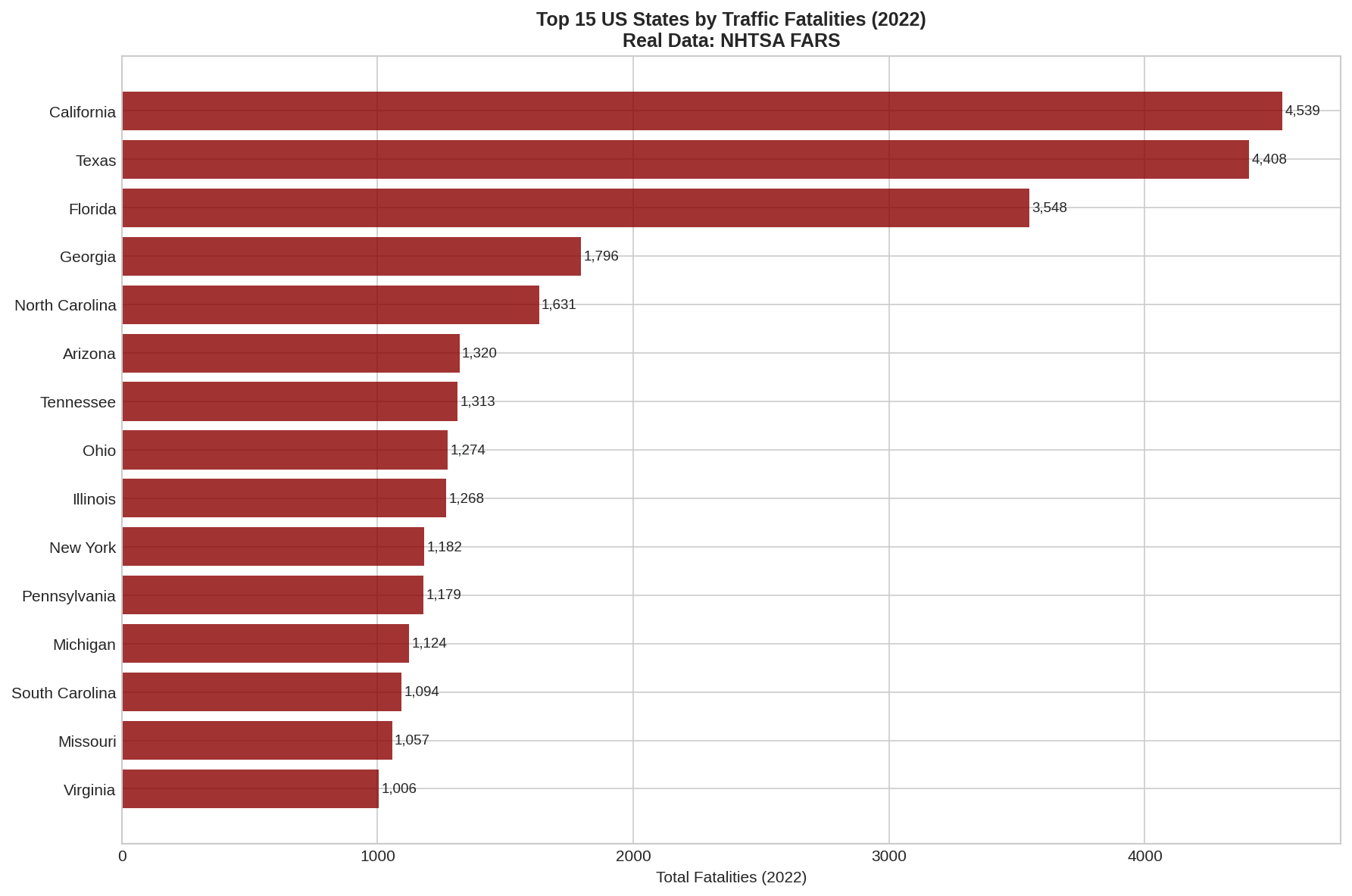
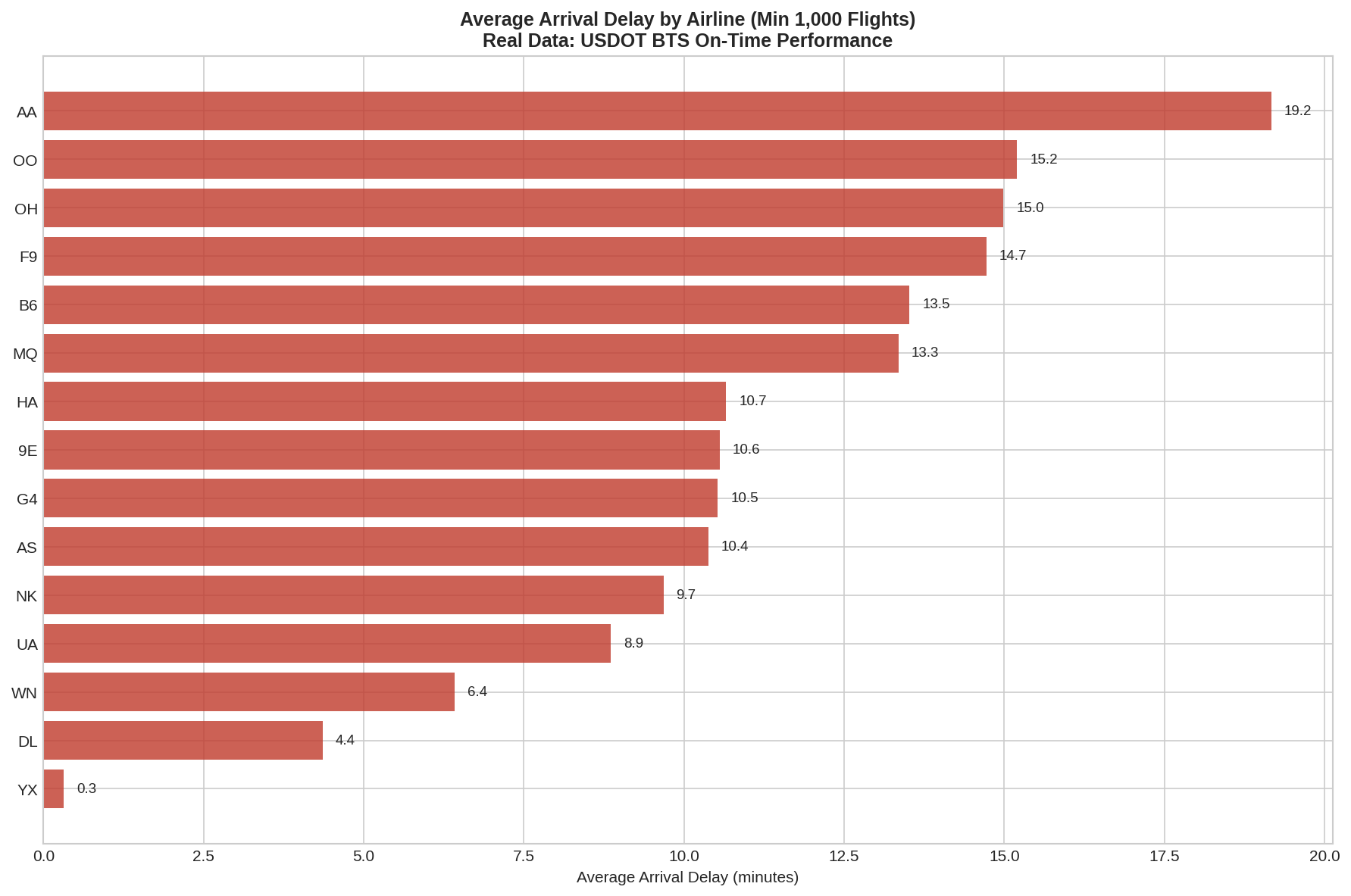
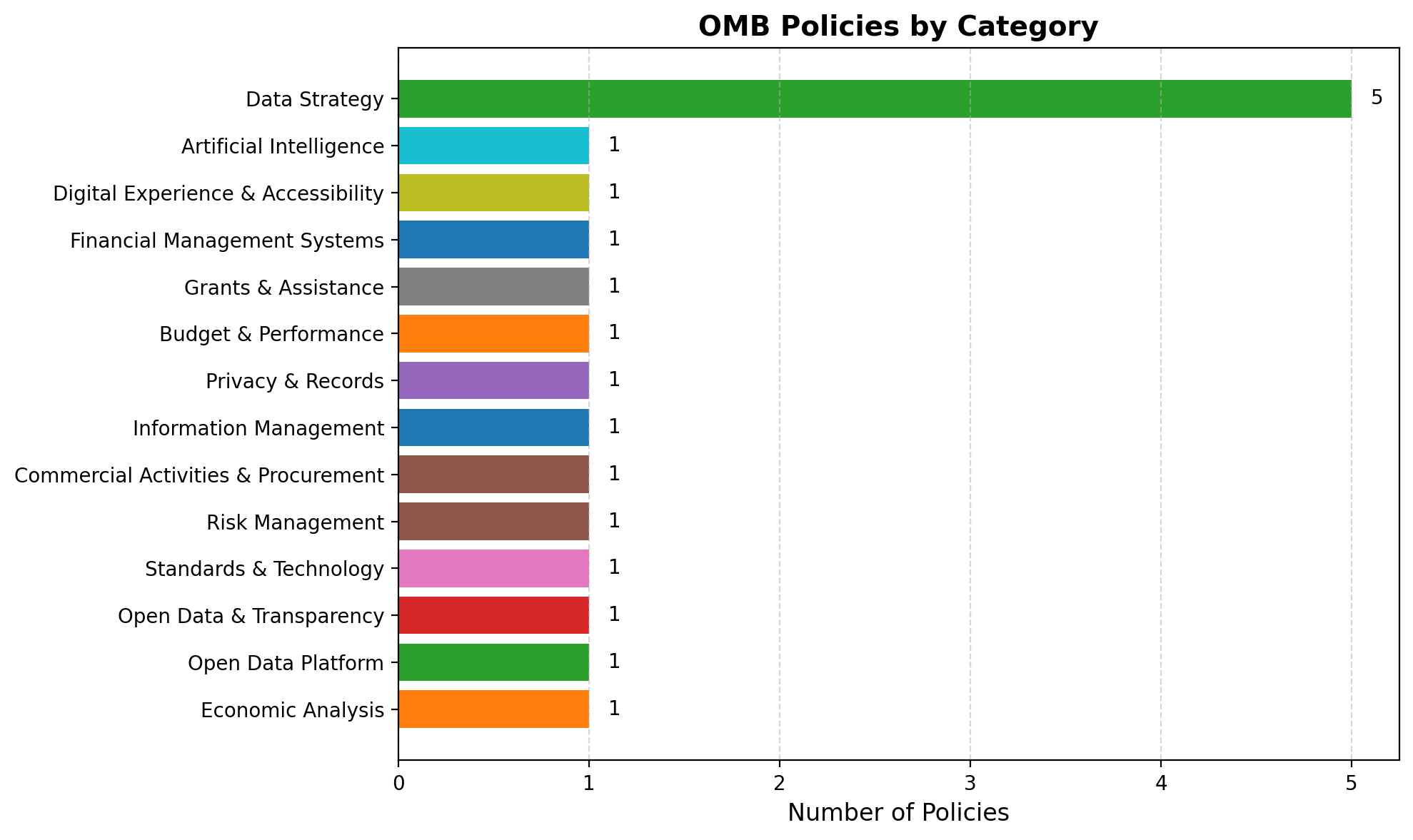
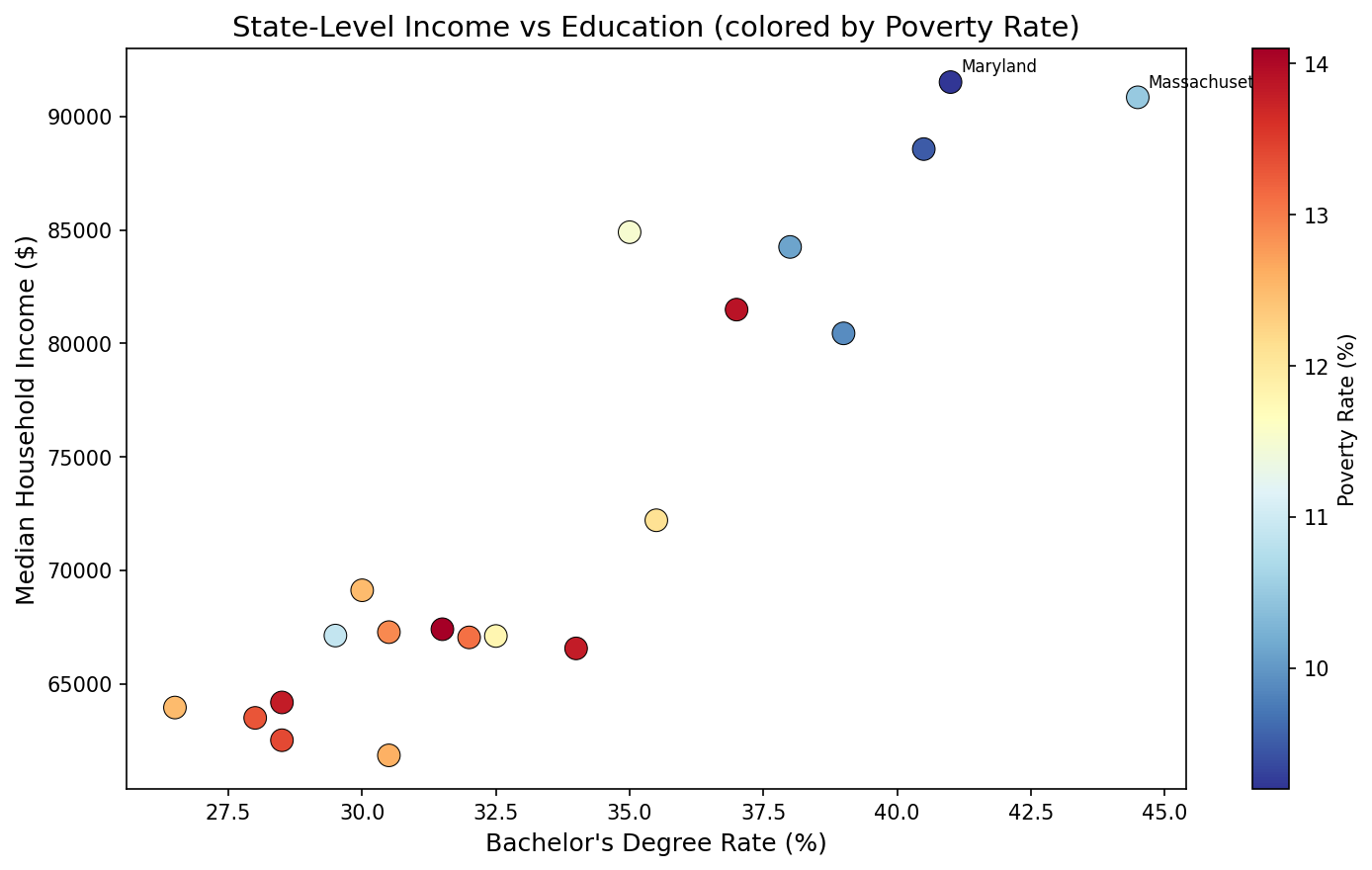
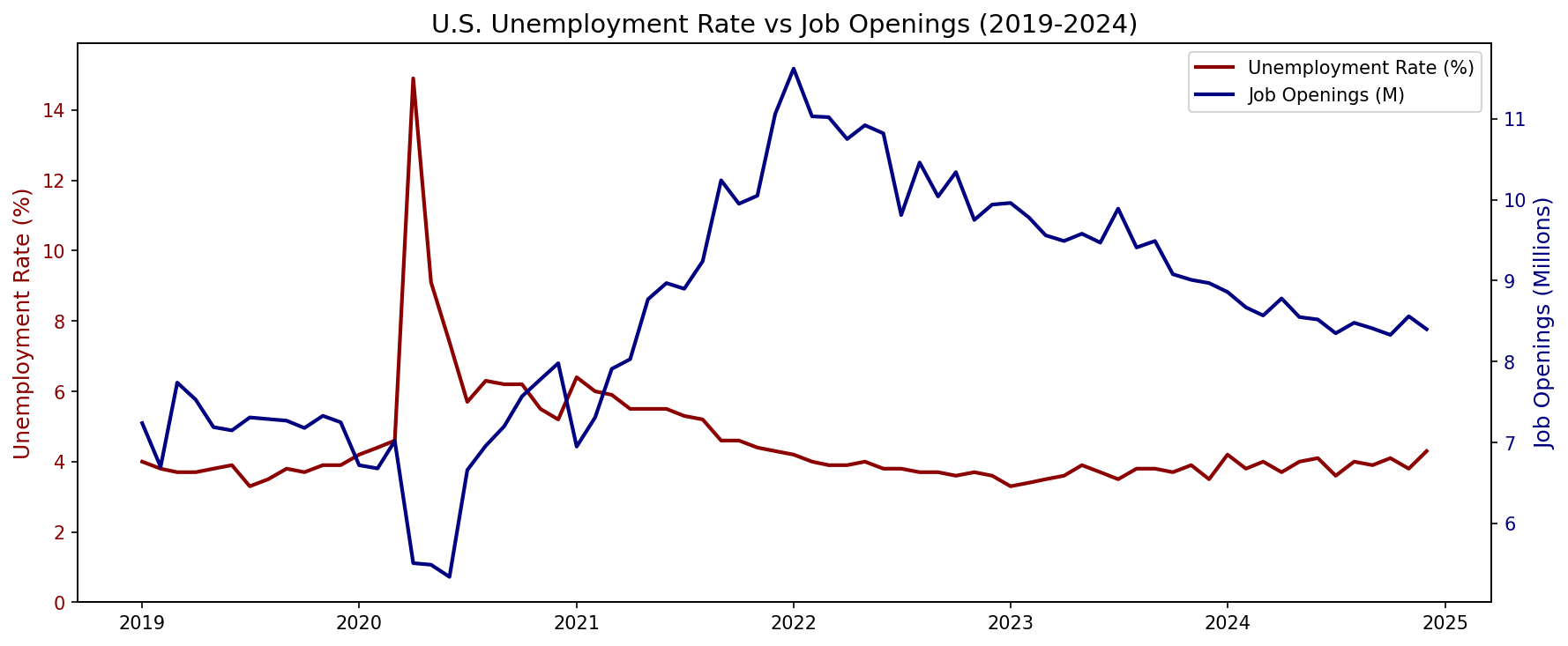
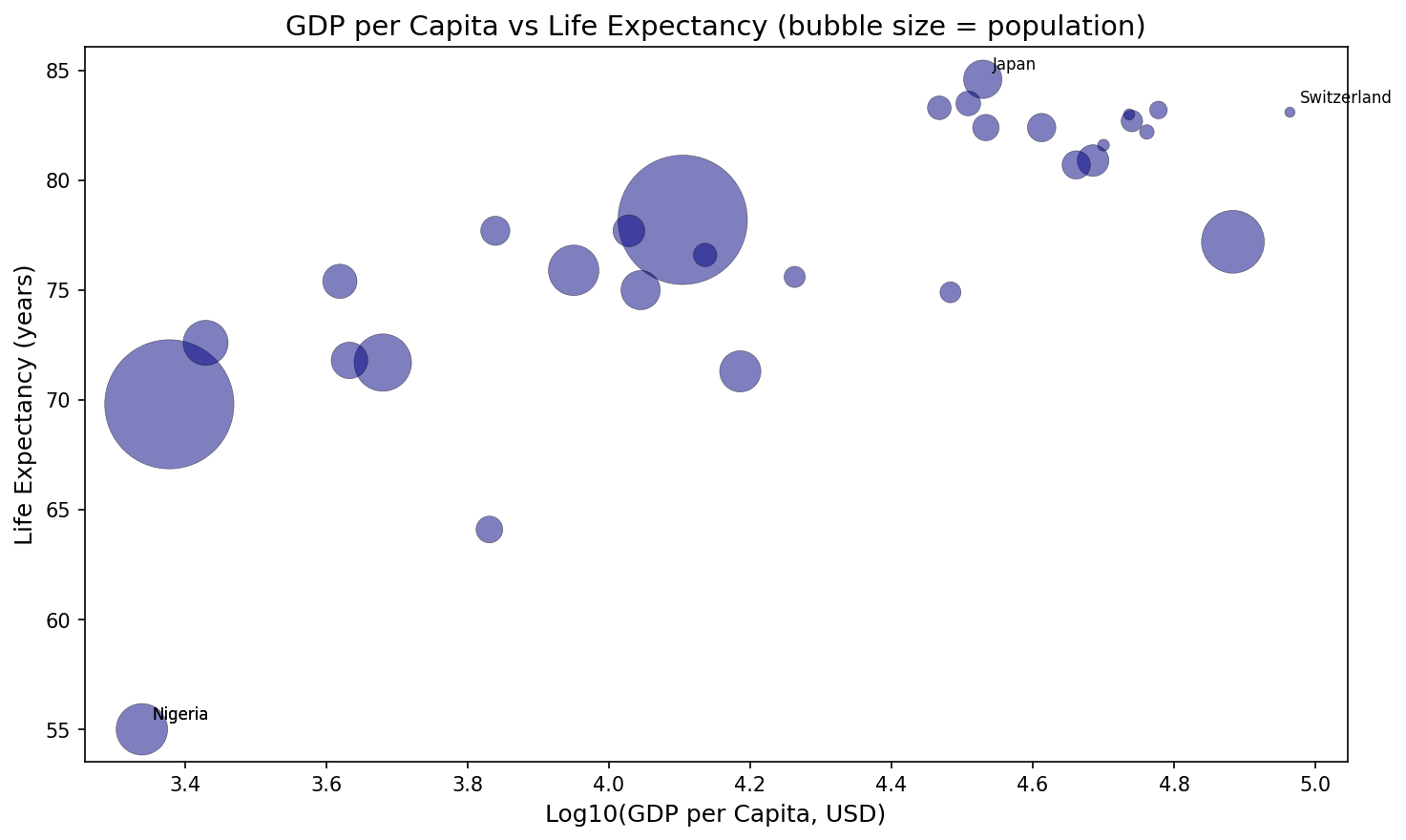
Sierra Napier
850M+
Real Records Analyzed
|
9
Live Repositories
|
28
Production Projects
|
50+
Notebooks
|
100%
Real Data
I analyze complex data at scale, architect AI systems that automate it, and visualize the story so stakeholders act on it.